 HammBurg Be informed with latest news, reviews, entertainment, lifestyle tips, and much more.
HammBurg Be informed with latest news, reviews, entertainment, lifestyle tips, and much more.
Data Analytics, enterprise dashboards, user applications and so much more need data sets they can use to store, read and write information. Currently, there are so many data architectures being used for these applications and so much more depending on the objective of that particular project.
Most use cases of data sets do include in-memory data grids or distributed caching. It is shocking to some to uncover that these two concepts do not mean the same thing. Here are clear definitions of each one and the differences between them.
What is an in-memory data grid?
Regardless of the application you are running, having data stored in memory is key to having a pleasant experience and reaching maximum productivity. To have this data ‘closer’ to the application, an in-memory data grid can be used. This data grid has one main focus, reducing the latency when querying data that could also be used to upload insights to a data store or warehouse.
Using key/value storing systems, data that is needed frequently can be queried faster and application APIs do not need to fetch it from the warehouse or database. These elements help with quicker loading and reduce the risk of the application crashing due to loading massive amounts of data all at once.
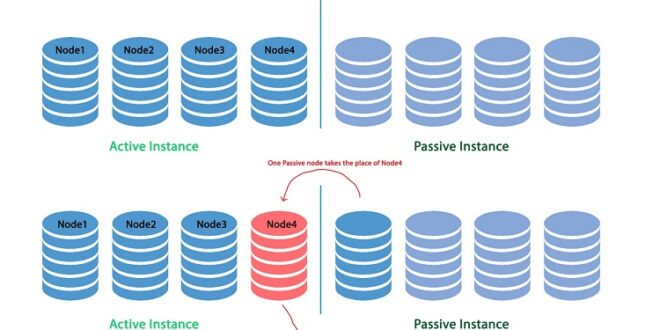
Snapshot of distributed cache systems
Distributed cache is a bit similar to in-memory data grids because its main focus is supporting the high availability of data. This system works both online and offline, with its main task of batching highly frequented data to access it quicker. Subsequently, applications using distributed cache systems do not need to directly access the data on the database or storage location.
Since it is stored on the process storage for higher availability, gaining access to it is much quicker and does not use much processing power. Overall, the application functions much more effectively and does not use too much processing power, which puts a strain on the user experience. Although these systems pretty much sound the same, there are some major differences between them.
Key differences between in-memory data grids and distributed cache
What are the key differences between in-memory data grids and distributed cache? The most notable difference between these two different systems is the architecture they use. Distributed caching systems use relevantly older technology and, as a result, face some bottlenecks when operating in conjunction with newer applications and systems.
On the other hand, in-memory data grids are designed for modernistic and futuristic applications with demanding requirements. Progressive tech organizations prefer using in-memory data grids because of their ability to handle complex queries. In retrospect, in-memory data grids were the product of advanced distributed cache development. Therefore, the key difference between these systems is the complexity of data sets each one can handle.
Supporting colocation of computations
The key benefit of distributed caching is the distribution of data across a cluster of nodes and in-memory data grids also offer these capabilities. However, the latter goes the extra mile by carrying out a more complex task called computation colocation.
As the data is cached on a cluster of nodes, in-memory data grids use them to compute that information. As a result, it uses the computing power of the nodes part of this advanced distributed cache. Thus, applications that use in-memory data grids do not suffer a lot when used in devices with smaller computing power. Supporting computation colocation is just one example of how in-memory data grids take distributed caching to the next level.
Using Massively Parallel Processing functionalities
Another difference between in-memory data grids and distributed caching is the ability to effectively use massively parallel processing functionalities. As mentioned, distributed caching activates multiple nodes to store data for higher availability. In extension to that capability and on top of supporting computation colocation, in-memory data grids allow MPP processes to take place.
These are simply computations that are undertaken using multiple nodes but in parallel with each other. MPP systems can be used in a variety of applications, including improving cybersecurity analyzing data quicker and more efficiently, etc. The integration of MPP systems improves the overall functionality of applications that have complex computation models.
Benefits of the in-memory data grid
In-memory data grids have proven to be a superior method of processing data for higher availability. This data management system takes things a step further by supporting more complex processing systems to improve the performance of enterprise applications. Using in-memory data grids also unlocks the potential of using full-scope data access layer systems such as Data Integration Hubs.
The predominant benefit of this data management system is its flexibility with integrating with other latest purpose-driven technologies. In comparison, a distributed caching system is restrictive in terms of integration with other data models, technologies, and systems. Its sole purpose is to make data highly available to applications that will need rapid access by storing it in the process storage.
Is distributed cache still relevant?
Although systems like in-memory data grids seem to be phasing distributed cache out, the truth is there are some applications that still use this system despite the fact that it is limited in integration capabilities in comparison with the in-memory data grid. However, applications that do not require complex computational data can very well use distributed cache to power their systems.
Complex systems that require computational data or applications which might need to scale in the future. In short, distributed cache systems are still relevant but when you choose to use them, do so under advisement.
The bottom line
In-memory data grids and distributed caching are not the same thing but they do share some similar tenets. The former can handle more complex requirements such as using MPP and computation colocation to the nodes it uses to cache data. On the other hand, distributed caching only caches data on multiple nodes and does not use it to conduct any computational processes. Additionally, in-memory data grids allow an agile development process with an elaborate data access layer system.


